
When data is skewed, it means that one category is represented more often when compared to the other data categories in a given dataset. Take Figure 2.19, which represents a right/positive skew, no skew, and a left/negative skew for the BCI electrodes. You might notice that the graph in the middle, with no skew, is symmetrical.
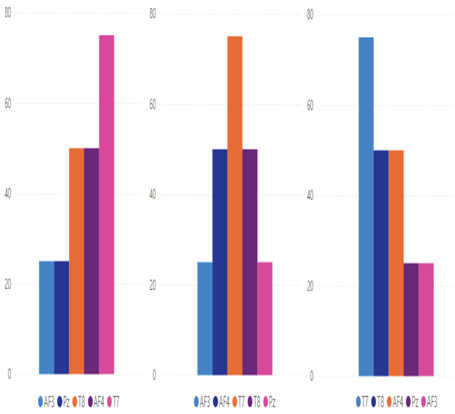
FIGURE 2.19 A data skew example
Uneven distribution of data across the nodes is known to cause latency in data query executions. You might remember the numerous examples of creating the READING table, one of which used a HASH with a distribution key of ELECTRODE_ID. In Figure 2.19 you can see that there is much more data relating to electrode T7 than any other. This would cause queries that include T7 as part of the query parameter to perform more slowly than others. This is because there is more T7 data. When you see a data skew like this, you need to reevaluate whether you have chosen the correct distribution key. Perhaps distributing the data onto the nodes using FREQUENCY_ID would result in a more even distribution of data across the nodes.
Processing Skew
The term processing skew has a lot to do with data skew. Basically, the more data that exists on a node, the more compute power required to retrieve it. Assume that all nodes in the SQL or Spark pool have the same number of CPUs and the same speed and amount of memory. A query run on a node with more data to parse would perform more slowly than when running that same query on a node with less data. Where data skew has the role of getting equal amounts of data onto each node, processing skew has to do with the compute power required to process such data.
Recursive SQL
A recursion is a term you will find not only in SQL but also in programming languages. Recursion in general is when an object refers to itself. In the context of recursive SQL, it means a SQL query that refers back to itself. The most efficient way to create a recursive query is by using common table expressions (CTEs), the structure of which is shown here:
WITH POW_CTE (SESSION_ID, ELECTRODE_ID, FREQUENCY_ID)AS(SELECT SESSION_ID, ELECTRODE_ID, FREQUENCY_ID FROM READINGWHERE READING_DATETIME> (SELECT dateadd(week, -1, getdate())))
SELECT ELECTRODE_ID, FREQUENCY_ID, VALUE
FROM POW_CTE
GROUP BY ELECTRODE_ID, FREQUENCY_ID
ORDER BY ELECTRODE_ID
Notice the WITH clause, which is a sure sign that some recursion is coming up. Be sure to watch out when using recursion because you can get into trouble and end up in an infinite loop. To avoid such possibilities, use the option MAXRECURSION, which you can set to a number of allowed recursion levels. The deeper you go, the more latent the query will become, so be careful and design precisely.



