
Hadoop external tables, created using the previous SQL syntax, are only available when using dedicated SQL pools and support CSV, parquet, and ORC file types. Notice in the following SQL syntax that there is no TYPE argument. The result of not identifying a TYPE is supported only on serverless SQL pools, with CSV and Parquet the supported file types. When there is no TYPE, the table is referred to as a native external table.
CREATE EXTERNAL DATA SOURCE MetalMusic_Source
WITH (LOCATION = ‘https://<accountName>.dfs.core.windows.net/<container>/<path>’)
Next, you create an external file format using the following SQL syntax. There is no difference in syntax here between dedicated and serverless:
CREATE EXTERNAL FILE FORMAT BrainwaveCSVFormatWITH ( FORMAT_TYPE = DELIMITEDTEXT,FORMAT_OPTIONS (FIELD_TERMINATOR = ‘͵’͵USE_TYPE_DEFAULT = FALSE))
The different values available for FORMAT_TYPE are PARQUET, ORC, RCFILE, and DELIMITEDTEXT. Notice that JSON or YAML is not included in this list and therefore cannot be managed using this feature directly. The FIELD_TERMINATOR only applies to delimited text files and identifies the end of each field. I recommend that you use one or more ASCII characters. A FALSE value for USE_TYPE_DEFAULT instructs the loader, aka PolyBase, to insert a NULL into the column when a value is missing. If the value is TRUE, then you can provide a default value, such as a 0 or an empty string “”. There are a few other options, which are summarized in the following list:
- DATA_COMPRESSION: The type of file compression used on the file being processed, if compressed
- org.apache.hadoop.io.compress.DefaultCodec
- org.apache.hadoop.io.compress.GzipCodec
- org.apache.hadoop.io.compress.SnappyCodec
- FIRST_ROW: Specifies the first row to be read in all files. If the first row is a header, then set this value to 2.
- DATE_FORMAT: The date can come in a wide range of formats; use this to make sure it gets transferred as expected.
- ENCODING: UTF8 or UTF16.
Now it is time to create the table itself. You can use the following syntax as an example, similar to that shown in Figure 2.13 and in the following code snippet
CREATE EXTERNAL TABLE MetalMusic([C1] DATETIME,[C2] DECIMAL(7,3),[C3] DECIMAL(7,3),
[C4] DECIMAL(7,3), [C5] DECIMAL(7,3),[C6] DECIMAL(7,3))WITH (LOCATION = ‘SessionCSV/MetalMusic/POW’,DATA_SOURCE = MetalMusic_Source, FILE_FORMAT = BrainwaveCSVFormat )
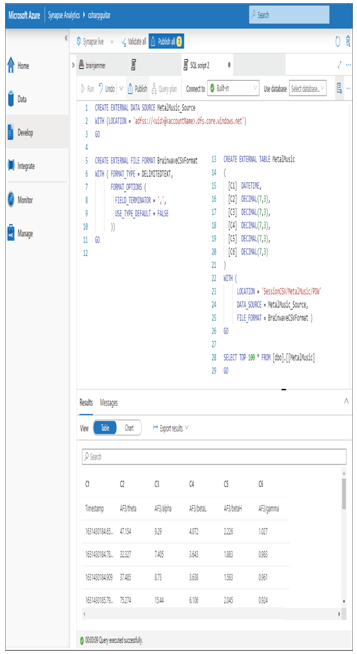
FIGURE 2.13 Azure Synapse Analytics external tables example
The LOCATION argument needs some additional clarification. While DATA_SOURCE and FILE_FORMAT are clear since they were created and named in the two SQL commands prior to the creation of the external table seen previously, the LOCATION argument identifies the location—in this case, of a group of files to load into the external table. The location value of SessionCSV/MetalMusic/POW results in all the files within the POW directory being included during the import process that brings the data within those files into the external table. Figure 2.14 illustrates a data directory hierarchy that is stored in an ADLS container named brainjammer.
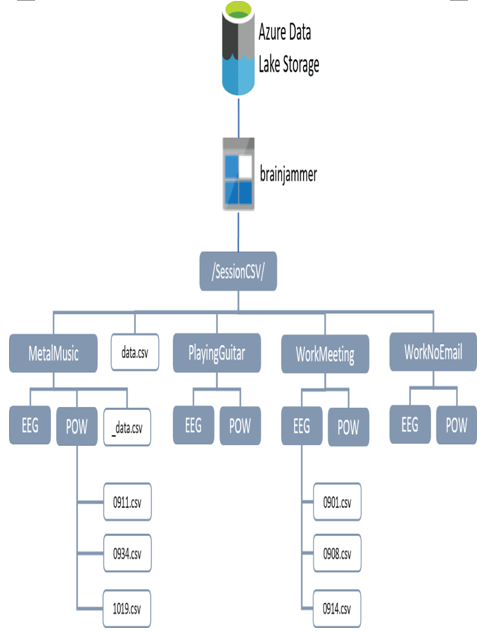
FIGURE 2.14 ADLS directory hierarchy example
Notice that there are two subfolders under the MetalMusic folder. Instead of using SessionCSV/MetalMusic/POW as the location, what might the result be if you used SessionCSV/MetalMusic? This is a trick question because it depends on which TYPE value you set for the data source. If you used HADOOP, then all the files within all the subfolders would have been queried and placed into the external table. But, had there been no TYPE, meaning the external table is considered native, it would have resulted in no files being processed. There is a file named _data.csv in the MetalMusic folder, but why wouldn’t that one be processed? That is because files or folders that begin with an underscore (_) are considered hidden and will be ignored. If you do want all the files in all subdirectories processed when the external table is native, you need to add two stars at the end of the path: SessionCSV/MetalMusic/**. Also, notice that there is a file named data.csv in the SessionCSV root directory. Had the location been set to only SessionCSV, what would the outcome be for both Hadoop and native external tables? Think about it first and then read on. The Hadoop external table would include all files from all the subfolders, excluding any file or folder that is hidden, whereas the native external table would have loaded only the data.csv file.
There are characters known as wildcards that can be used to set the location. Read through Table 2.4 to gain more knowledge about the types of wildcard characters that can be used to search folder, file paths, or filenames.
TABLE 2.4 Wildcard location examples
| Symbol | Example | Description |
| * | /MetalMusic/POW/*.csv | Gets all CSV files in the POW directory |
| ** | /MetalMusic/**/*.csv | Gets all CSV files under MetalMusic |
| ? | */*/POW/?901.csv | Gets all CSV files in all POW directories where the filename has one character before a 901 |
| [ ] | */*/POW/[09].csv | Gets all CSV files in all POW directories that begin with 09 |
When you set a location using a wildcard path, it will search through the entire storage directory looking for pattern matches. This is a very powerful feature. You will do some of this wildcard searching in later chapters. A few other external table arguments are worthy of some additional explanation:
- REJECT_TYPE
- REJECT_VALUE
- REJECT_SAMPLE_VALUE
- REJECTED_ROW_LOCATION
These arguments are used to instruct PolyBase when to abort the query and data transport process. REJECT_TYPE can be either a value or a percentage. If REJECT_TYPE is set to value and REJECT_VALUE is set to 5, if PolyBase rejects five rows of data, the query will fail. Remember that when you created the external table you defined the column data types. A reason why a row may fail (i.e., be rejected) is because the column in the source does not match the destination column data type. If REJECT_TYPE is set to percentage, then PolyBase will keep a running tally of the ratio between success and failure. The query will fail if the failure rate breaches the set percentage threshold. If the threshold is 30, and 31 of 100 rows have failed to migrate, the query stops. How often would you like PolyBase to calculate the percentage? You set this using the REJECT_SAMPLE_VALUE. If set to 1000, then after 1,000 migrated rows, PolyBase will check the success/failure percentage rate and take appropriate actions. PolyBase can create a log and store the rows that have failed to migrate in the location placed into REJECTED_ROW_LOCATION. By default, a folder named _rejectedrows is created in that location and the logs and data are written into it.



