
This distribution model uses a function to make the distribution, as shown in Figure 2.10. For large table sizes, this distribution model delivers the highest query performance. Consider the following snippet, which can be added to the script that creates the READING table:
DISTRIBUTION = HASH([ELECTRODE_ID])
This results in the data being deterministically distributed across the nodes based on the electrode type (i.e., AF3, AF4, T7, T8, or Pz) that captured the brainwave reading. A query that contains AF3 in the WHERE clause would be executed on the compute node that contains the data where ELECTRODE_ID = 1—that is, AF3. The column name parameter sent to the HASH function is known as the distribution key or distribution column.
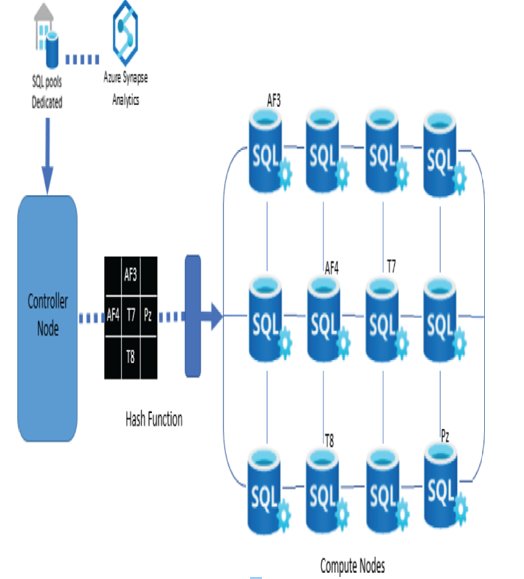
FIGURE 2.10 Azure Synapse Analytics hash table distribution
REPLICATED
This approach copies all the data from the entire table to each node. This mode delivers the best query performance for small tables. Figure 2.11 illustrates the copying of a table to the SQL pool nodes. As you might expect, the requirement for additional storage is necessary to store the multiple copies of the data on each node. Again, this is another reason when using this mode is best for small tables.
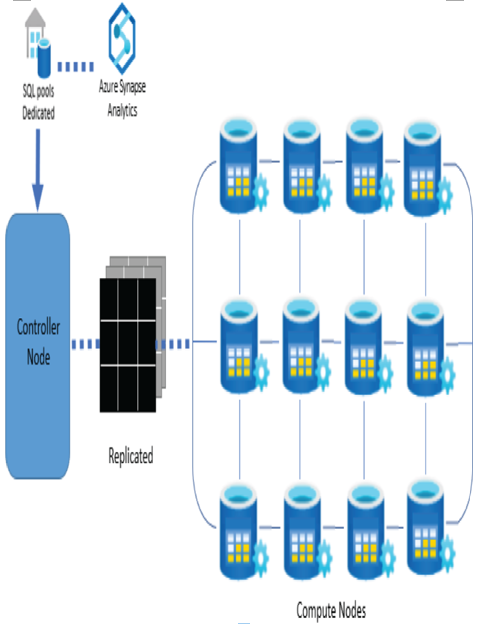
FIGURE 2.11 Azure Synapse Analytics replicated table distribution
The following snippet of SQL shows how to create a table and configure it as replicated:
CREATE TABLE [dbo].[READING_REPLICATE]WITH(HEAP, DISTRIBUTION = REPLICATE )AS SELECT * FROM [dbo].[READING]
Notice that the index is set to HEAP, which makes sense because the data tables will be small. It’s not a highly prioritized approach that the data is organized in any specific manner when the dataset is relatively small. Also notice the AS SELECT statement at the end of the query. This is discussed in the next section.
Create Table as Select
A Create Table as Select (CTAS) statement is one that generates a table using the output of a SELECT statement. CTAS is a very powerful command that can be used for, but not limited to, changing the distribution mode and indexes. A very primitive approach to achieving a similar output of a CTAS command is using the INTO statement. The following statement creates a new table called READING_NEW, identical to the READING table, and copies all the data into READING_NEW:
SELECT * INTO READING_NEW FROM READING
That is the most direct way to get a copy of a table. If you wanted to change DISTRIBUTION, INDEX, or even a PARTITION, you could perform the following:
CREATE TABLE [dbo].[READING_NEW]WITH( DISTRIBUTION = ROUND_ROBIN, HEAP, PARTITION ([ELECTRODE_ID] RANGE RIGHT FOR VALUES(1, 2, 3, 4, 5)))ASSELECT *FROM [dbo].[READING];
If you recall from an earlier example in the “Partition” section, the READING table was created with a CLUSTERED COLUMNSTORE INDEX, a HASH distributed table on SCENARIO_ID and a partition on the eight different scenarios. This new table, READING_NEW, changed the distribution model, index, and partition, as you can see. Not only is the table structure replicated on the new table, but the data is copied as well. You can execute the following SQL commands to replace the existing table with the new one:
RENAME OBJECT READING TO READING_OLD
RENAME OBJECT READING_NEW TO READING
DROP TABLE READING_OLD
The first command renames the existing table by adding a suffix of _OLD. Then the new table, READING_NEW, is renamed to READING. Once you are sure that all worked as expected, you no longer need the old table, so you execute a DROP TABLE command to delete it.



