
When you’re working with external tables, the following data types are not supported:
- Geography
- Geometry
- Hierarchyid
- Image
- Text
- nText
- XML
- Any user‐defined type
Unsupported Table Features
Here is a list of unsupported Azure Synapse Analytics dedicated SQL pool features:
- User‐defined types
- Unique indexes
- Triggers
- Synonyms
- Sparse columns
- Sequence
- Indexed views
- Computed columns
Schema
A schema is an organization feature found in a database. Imagine a large relational database where you have over a thousand tables. You would hope that there is great documentation that can help you discover and understand what tables exist and how to interpret the data that is in them. It would be even better if there was a way to group similar tables together, and there is—it’s called a schema. The default schema in Azure SQL is [dbo], which you have seen already in numerous places so far. You create a schema using the following syntax.
CREATE SCHEMA views
AUTHORIZATION dbo
That syntax created a schema named views and granted user dbo access to it. As you can see in Figure 2.15, there are tables that are prefixed with schema dbo and views that are prefixed with the schema name. Both schemas have granted access to the dbo user, which is the default user account.
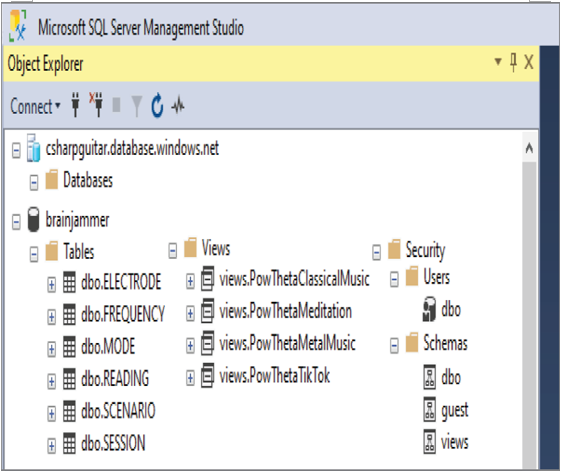
FIGURE 2.15 Schemas, views, and users as seen in SSMS
Note that you can also create a schema using PySpark with this syntax. The following snippet running in a Notebook attached to a Spark pool within Azure Synapse Analytics Studio will create a schema. The schema in the context of PySpark is a little different than with a SQL schema. In this context the schema is concerned with the structure and type of data, instead of being a logical unit of control to isolate tables as it is with a SQL schema. This will become clearer as you read through the next few sections.
%%pyspark
data =’abfss://<uid>@<accountName>.dfs.core.windows.net/SessionCSV/MetalMusic/POW’
df = spark.read.format(‘csv’).option(‘inferSchema’, True).load(data)
df = spark.createDataFrame(data, schema=skema)
Once the schema is created, the output of df.printSchema() results in the following. The CSV files have 26 columns and therefore there are 26 total columns in the output, shown summarized for brevity, followed by the summarized output of df.show(2).
root | — _c0: string (nullable = true)| — _c1: string (nullable = true)| — _c2: string (nullable = true)| — _c3: string (nullable = true)| — _c4: string (nullable = true) …
+————-+———–+———–+———–+———–+———–+
| Timestamp | AF3/theta | AF3/alpha | AF3/betaL | AF3/betaH | AF3/gamma |…
| 1627801… | 110.994 | 25.473 | 3.987 | 0.483 | 0.242 |…
| 1627801… | 108.518 | 22.73 | 3.625 | 0.468 | 0.264 |……
Stored procedures, data types, views, primary and foreign keys, and so forth can also be created and organized into a schema. The point here is that a schema is not limited to tables only. In many respects, a schema can be referred to as a container of related data objects within a larger database. You might also see the word schema used to define the structure of a table. A table schema is one that contains the definition of a table, which typically includes column names and data types. A simple example of a table schema is provided here:
CREATE TABLE MODE([MODE_ID] INT NOT NULL,[MODE] NVARCHAR (50) NOT NULL)
Mostly, a schema is useful in giving structure and organization to the data, which is contained on your data platform, whether it be structured or semi‐structured. Schemas can help give a little order to the data management activities.



